[Linux]부트캠프 - 파일 및 폴더 생성
파일 및 폴더 생성

[Noitce] 고쳐야하거나 틀린 것이 있으면 말씀해주세요!
import numpy as np
import pandas as pd
import math
from scipy.stats import *
import scipy as sp
# Jupyter Notebook의 출력을 소수점 이하 3자리로 제한
%precision 3
# Dataframe의 출력을 소수점 이하 3자리로 제한
pd.set_option('precision', 3)
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity="all"
x = [1,2,3,4,5]
np.mean(x)
np.array(x).mean()
pd.Series(x).mean()
3.0
3.0
3.000
# 누구나 파이썬 통계분석 p.31
df = pd.read_csv('./data/ch2_scores_em.csv',
index_col = 'student number')
df.head()
| english | mathematics | |
|---|---|---|
| student number | ||
| 1 | 42 | 65 |
| 2 | 69 | 80 |
| 3 | 56 | 63 |
| 4 | 41 | 63 |
| 5 | 57 | 76 |
df.shape # 50행 2열
(50, 2)
# sum(), len()를 이용한 산술평균
# 영어 과목의 평균
sum(df['english'])/len(df['english'])
58.380
# numpy
np.mean(df['english'])
58.380
# pandas
df['english'].mean()
58.380
# scipy
sp.mean(df['english'])
<ipython-input-9-2043e7dc93a5>:2: DeprecationWarning: scipy.mean is deprecated and will be removed in SciPy 2.0.0, use numpy.mean instead
sp.mean(df['english'])
58.380
data = [2,8,3]
# 산술평균
np.mean(data) # 433%
4.333333333333333
# 기하평균 math.prod(data) = 데이터들을 다 곱해줌
math.prod(data)**(1/len(data))
3.634
# scipy.stat.gmean(a[, axis, dtype, weights]) 이용 기하평균
gmean(data)
3.634241185664279
# 조화평균 계산
data = np.array([80, 120])
1/data
len(data)/np.sum(1/data)
array([0.013, 0.008])
95.99999999999999
# scipy.stat.hmean(a[, axis, dtype]) 이용 조화평균
hmean(data)
95.99999999999999
# numpy.average 이용 가중평균
np.mean(np.arange(1,11)) # 산술
np.average(np.arange(1,11))
np.average(np.arange(1,11), weights=np.arange(10, 0, -1))
5.5
5.5
4.0
# 예제 데이터
scores = np.array(df['english'])
scores
array([42, 69, 56, 41, 57, 48, 65, 49, 65, 58, 70, 47, 51, 64, 62, 70, 71,
68, 73, 37, 65, 65, 61, 52, 57, 57, 75, 61, 47, 54, 66, 54, 54, 42,
37, 79, 56, 62, 62, 55, 63, 57, 57, 67, 55, 45, 66, 55, 64, 66],
dtype=int64)
# 순서 통계량
sorted_scores = np.sort(scores)
sorted_scores
array([37, 37, 41, 42, 42, 45, 47, 47, 48, 49, 51, 52, 54, 54, 54, 55, 55,
55, 56, 56, 57, 57, 57, 57, 57, 58, 61, 61, 62, 62, 62, 63, 64, 64,
65, 65, 65, 65, 66, 66, 66, 67, 68, 69, 70, 70, 71, 73, 75, 79],
dtype=int64)
# median 계산식
n = len(sorted_scores)
if n%2 == 0:
x1 = sorted_scores[n//2-1]
x2 = sorted_scores[n//2]
median = (x1+x2)/2
else:
median = sorted_scores[(n+1)//2-1]
median
57.5
sorted_scores[24], sorted_scores[25]
(57, 58)
# numpy의 median() 함수
np.median(scores)
# pandas.DataFrame median
df['english'].median()
57.5
57.500
예시) 평균이 2백만원, 표준편차 50만원인 정규 분포를 따르는 소득 데이터 100개 생성
np.random.seed(3)
income = np.random.normal(2000000, 500000, 100)
income[:10]
array([2894314.237, 2218254.925, 2048248.734, 1068253.648, 1861305.899,
1822620.51 , 1958629.259, 1686499.662, 1978090.916, 1761390.985])
# 평균 소득
np.mean(income)
1945681.4627969689
소득이 10억인 사람 추가
income = np.append(income, 10**9)
# 평균 소득
np.mean(income)
11827407.38890789
# 중앙값
np.median(income)
1919743.318406538
# scipy.stats.trim_mean(a, proportioncut[, axis]) 이용
trim_mean(income, 0.2)
1941471.0812132563
np.random.seed(3)
data = np.random.choice(['A','B','C'], 1000)
# A, B, C라는 요소로 이루어진 데이터
data[:10]
len(data)
array(['C', 'A', 'B', 'A', 'A', 'A', 'B', 'B', 'C', 'B'], dtype='<U1')
1000
# scipy.stats.mode(a, [axis, nan_policy]) 이용 최빈값 계산
# 최빈값과 빈도 반환
mode(data)
# 최빈값
mode(data).mode
# 빈도
mode(data).count
ModeResult(mode=array(['A'], dtype='<U1'), count=array([350]))
array(['A'], dtype='<U1')
array([350])
# pandas.Series의 value_counts()를 이용해 첫번째 결과가 최빈값
pd.Series(data).value_counts().index[0]
pd.Series(data).value_counts()[0]
'A'
350
# 데이터 생성
np.random.seed(123)
data = np.random.normal(100, 20, size=1000)
data[:10]
array([ 78.287, 119.947, 105.66 , 69.874, 88.428, 133.029, 51.466,
91.422, 125.319, 82.665])
# 정렬후 인덱싱 이용
sorted(data)[0],sorted(data)[-1]
# 최소, 최대
(35.37889984161376, 171.43158436052622)
# numpy : min(), max()
np.min(data)
np.max(data)
35.37889984161376
171.43158436052622
# numpy.percentile(a, q[, axis, out, ...])
# 제1사분위수(Q1. 하사분위수)
np.percentile(data, 25)
# 제2사분위수(Q2, 중위수)
np.percentile(data, 50)
# 제3사분위수(Q3, 상사분위수)
np.percentile(data, 75)
86.30886819268538
99.17628889574436
113.37731495435875
import matplotlib.pyplot as plt
plt.boxplot(data)
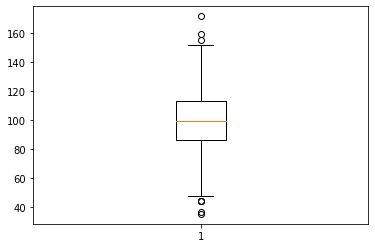
describe(data)
# scipy.stats.describe
describe(df['english']) # 표본데이터의 기술 통계량
DescribeResult(nobs=1000, minmax=(35.37889984161376, 171.43158436052622), mean=99.20871727838417, variance=401.03130940853094, skewness=-0.029040113501245676, kurtosis=-0.02543852877769215)
DescribeResult(nobs=50, minmax=(37, 79), mean=58.38, variance=96.03632653061224, skewness=-0.31679325324962426, kurtosis=-0.38870454364589113)
# pandas
df['english'].describe()
count 50.00
mean 58.38
std 9.80
min 37.00
25% 54.00
50% 57.50
75% 65.00
max 79.00
Name: english, dtype: float64
describe(df['english'], ddof=0) # 모집단 데이터에 대한 기술 통계량
DescribeResult(nobs=50, minmax=(37, 79), mean=58.38, variance=94.1156, skewness=-0.31679325324962426, kurtosis=-0.38870454364589113)
import numpy as np
# numpy float 출력옵션 변경
# np.set_printoptions(precision=3)
# np.set_printoptions(precision=20, suppress=True)
# pd.options.display.float_format = '{:.2f}'.format
np.set_printoptions(formatter={'float_kind': lambda x: "{0:0.3f}".format(x)})
np.random.seed(123)
data = np.random.normal(100, 20, size=1000)
data[:10]
array([78.287, 119.947, 105.660, 69.874, 88.428, 133.029, 51.466, 91.422,
125.319, 82.665])
# numpy를 사용해 범위구하기
np.min(data), np.max(data)
np.max(data)-np.min(data)
# numpy ptp(a[,axis,out,keepdims]) 이용 범위 계산
np.ptp(data)
(35.37889984161376, 171.43158436052622)
136.05268451891246
136.05268451891246
# 중간 범위 계산
(np.max(data)+np.min(data))/2
103.40524210106999
# numpy.quantile() 이용 IQR 계산
np.quantile(data, 0.75) - np.quantile(data, 0.25)
# scipy.stats.iqr(x[,axis, rng, scale, nan_policy, ...]) 이용
iqr(data)
27.06844676167337
27.06844676167337
(np.quantile(data, 0.75) - np.quantile(data, 0.25))/2
iqr(data)/2
13.534223380836686
13.534223380836686
data-np.mean(data)
array([-20.921, 20.738, 6.451, -29.335, -10.781, 33.820, -47.742, -7.787,
26.110, -16.544, -12.786, -1.103, 30.619, -11.987, -8.088, -7.896,
44.910, 44.527, 20.872, 8.515, 15.539, 30.606, -17.925, 24.308,
-24.286, -11.964, 18.933, -27.782, -2.010, -16.444, -4.321,
-55.180, -34.639, -13.206, 19.341, -2.681, 0.848, 14.556, -16.799,
6.464, -15.316, -33.762, -7.027, 12.267, 7.563, 0.555, 48.639,
9.050, 20.366, 45.554, -25.090, -19.984, 35.666, -15.170, 1.385,
22.178, 18.605, 35.889, 30.704, 22.179, -14.663, 16.689, 7.077,
-25.734, 29.137, 16.936, 1.701, -3.871, -23.175, 4.782, 10.160,
-15.832, 24.035, -21.153, -41.671, 21.586, -7.276, -1.729, -15.959,
-31.328, 25.896, -12.986, 34.010, 16.937, -5.504, -20.927, -13.858,
-23.459, 42.534, 4.080, 23.795, -24.556, 4.412, 24.349, -5.909,
21.414, -20.900, -26.478, 8.379, -6.792, 13.632, -38.766, 15.037,
52.757, 0.299, 1.474, 4.382, -36.448, 9.314, -31.317, -7.762,
25.649, -13.913, 10.816, 21.046, 6.366, -26.628, -5.858, 39.980,
-39.710, -4.724, -10.251, 3.206, 15.756, 32.965, -4.613, 17.038,
10.786, 10.278, -10.487, -19.155, -21.210, -14.337, 7.225, 16.010,
7.261, -10.188, 36.911, 31.169, -6.289, -15.677, 3.396, 26.137,
7.447, 11.922, -3.450, 9.917, 31.682, -4.002, 3.657, 5.868, 6.466,
-27.446, -36.746, -19.602, 4.150, 11.868, -9.822, 28.336, -2.072,
1.198, -3.088, 3.472, 14.881, 14.104, -17.177, 31.265, -21.109,
2.376, -4.697, -20.189, -0.711, -14.025, 2.249, 8.853, 30.230,
6.939, -11.433, -7.041, 3.591, 2.660, 29.983, 28.698, -6.387,
-10.182, -50.350, -10.187, -18.770, -6.305, 8.623, 4.335, 0.192,
4.783, -1.731, 4.732, -63.830, -4.595, -1.426, -6.034, -3.568,
14.857, -11.171, 44.805, 14.557, 0.665, -3.342, -0.939, -17.515,
-1.113, 6.365, 12.382, 12.385, -4.706, -27.530, -12.591, 33.035,
18.712, 8.184, -14.435, 0.864, -24.322, -10.247, -4.113, -6.442,
19.923, -27.583, -16.517, -26.702, -23.956, 3.272, -31.218, 15.869,
-4.145, 2.167, 7.243, -7.892, 21.441, -3.096, 12.673, -3.191,
6.609, 6.385, 5.791, -18.695, 9.509, -5.588, 13.401, -42.259,
-28.511, 8.060, 38.050, 17.492, -12.858, -33.050, 15.645, -0.820,
12.605, 3.097, 1.384, 59.964, 0.669, -2.394, -1.638, -10.879,
20.594, -6.284, 13.510, 6.483, 25.171, 9.195, -23.476, -25.738,
28.959, -11.383, -25.621, -12.601, 26.084, -27.613, -16.539,
-12.545, -24.233, -22.895, -29.571, -8.432, -6.307, -12.859,
-32.283, 25.858, -25.790, 6.352, -20.704, 14.158, 19.908, -16.761,
-37.683, 14.707, 38.307, 9.105, 4.002, 17.186, 16.092, -15.788,
-12.392, 13.014, -2.089, 27.123, -13.296, 15.803, 7.644, -1.737,
24.309, 14.393, -19.308, 13.596, 28.291, -1.818, -4.182, -12.602,
0.519, 14.515, -15.562, -26.136, -6.724, -26.803, 11.256, -7.743,
-34.317, -6.181, -3.061, 9.774, -2.116, 38.166, -9.583, -0.457,
-1.267, -4.861, 3.640, 11.616, 27.593, -30.594, -9.416, -8.164,
19.548, -6.342, -37.112, 2.546, 0.117, 4.386, -20.012, 35.172,
-5.686, -2.975, -17.209, -17.829, -23.663, -7.075, -18.360, 41.921,
-36.979, -21.775, -7.237, 14.261, -7.484, 14.311, -18.945, 1.977,
35.672, -18.564, 9.183, 4.930, -44.239, -10.988, 23.414, 3.493,
-23.454, 14.607, -8.791, 7.992, 8.330, -21.583, 16.588, -19.359,
-25.324, -16.865, -6.131, 2.979, -14.660, 15.688, 5.821, -13.105,
18.571, 24.013, -1.182, -3.508, -34.684, -7.359, -5.039, 5.699,
-2.577, 5.672, 31.473, -9.807, -9.028, -25.392, 0.618, 20.328,
-34.230, -12.526, 1.510, 17.793, 8.449, 7.301, -3.695, 10.429,
21.077, -33.389, 15.362, -1.184, -9.808, -48.070, -26.816, 34.752,
-12.980, -20.904, -8.337, -14.112, 3.278, 31.131, -10.941, 3.877,
-22.153, 31.195, 4.572, -20.845, 18.877, 24.791, 4.020, -31.997,
36.495, 6.994, 24.200, -10.227, -7.181, 3.000, 23.059, 3.651,
-24.345, 6.031, 33.382, 2.107, 3.379, -24.460, -27.268, -11.963,
-5.739, 2.872, 4.110, 32.829, 1.965, 22.080, 0.005, 29.769,
-36.617, -11.183, 20.452, -2.641, 19.422, 8.493, 19.709, 13.053,
14.264, 30.640, 20.521, 20.667, 1.200, -10.846, -12.400, 15.810,
-47.978, -25.352, -18.474, -4.161, -51.837, 25.966, 12.795, 40.483,
22.036, 21.399, 45.805, -10.628, -29.278, -3.856, -15.709, -4.346,
-20.213, 12.149, 11.051, 0.253, 7.023, -2.050, 15.832, 2.184,
-4.518, 19.383, 26.008, 27.540, -19.014, -9.898, -33.239, -3.980,
9.114, -1.865, 39.408, -7.326, -20.979, 12.161, 3.790, 11.784,
6.867, 5.667, -41.655, -13.731, -11.015, -6.168, -8.177, 9.048,
12.809, -21.842, 14.527, 12.507, 10.107, -27.567, 9.603, 2.443,
20.009, 36.478, 32.553, 3.044, 0.754, 13.430, -21.510, -28.222,
-8.659, 25.203, -5.831, 30.843, -54.971, -30.953, -1.682, 18.555,
-0.601, -1.122, -1.644, -34.467, 23.953, -12.864, 22.582, -0.619,
22.154, 7.656, -1.342, 5.317, -28.668, 0.912, 35.112, 26.955,
-18.909, 10.905, 5.751, 17.135, 2.674, -3.879, 27.404, 5.119,
25.901, 20.279, -5.698, -2.549, 39.388, 4.621, -14.381, -23.210,
20.274, 3.997, -15.051, 14.283, 3.986, -32.418, 12.565, 27.455,
51.988, 1.489, 5.444, 32.923, 4.166, 6.298, -11.821, -27.096,
19.045, -24.680, 23.604, -14.972, 6.096, -6.654, 24.283, 6.808,
39.973, -20.882, 9.069, 1.738, 6.390, 32.710, 12.498, -22.159,
11.461, -7.521, -8.676, 21.708, -11.256, -6.803, 1.439, 19.715,
12.423, -3.897, -4.652, -22.411, -14.405, -12.296, -2.195, 40.527,
-12.718, -5.125, -40.257, 12.803, -30.758, -17.341, 21.638,
-41.307, 2.710, 16.810, 31.300, -17.611, -11.689, 36.880, 0.290,
-13.934, -13.558, -18.660, -8.002, 22.556, 18.547, -22.694, 5.083,
-7.252, 16.440, -2.336, 8.222, -2.381, -42.950, 1.731, -24.644,
15.734, -12.805, -11.309, 0.613, 12.347, -2.604, 33.635, 33.768,
35.101, -3.895, -28.848, 25.193, -7.536, 1.555, 13.358, -31.297,
33.374, 18.291, 7.837, 18.610, 11.930, 3.128, -5.364, -13.992,
6.536, 8.015, 22.455, 4.804, -16.273, -30.733, -1.760, 0.242,
-1.171, -29.819, 22.281, 22.244, -15.674, 16.911, 19.848, 1.560,
-18.179, 33.059, 8.410, -4.229, 16.248, 33.235, -9.152, 14.620,
39.654, -21.540, -10.194, -11.166, -2.375, -3.408, 6.807, -15.616,
-11.662, 6.817, 3.890, 18.273, 8.978, 16.228, -22.068, -6.877,
37.759, 8.633, 15.739, 6.246, 9.298, -3.827, 72.223, -7.132, 0.025,
-47.705, 22.917, -10.254, -0.425, -9.770, -1.982, -4.894, -0.070,
-0.265, -2.293, -2.566, 26.962, 18.420, 18.540, -13.858, 25.928,
23.424, -10.277, 31.268, -12.873, -36.049, 22.822, -1.599, 20.330,
-14.293, -24.444, 25.429, -27.354, -30.429, -37.720, -55.098,
-19.991, -42.597, 0.079, -43.937, -21.094, 47.433, 7.694, 1.847,
-31.624, -4.121, 1.753, -31.312, 3.315, 24.616, -6.174, -3.153,
-40.051, -27.193, 21.945, -12.440, -17.803, -13.060, -0.358,
-22.377, 3.322, -26.409, 16.271, -20.350, 27.197, 0.591, -16.122,
19.020, -26.699, -10.150, 0.790, -1.632, -39.380, -17.622, 4.156,
-25.607, 26.120, 10.695, -9.494, -3.615, 38.023, 19.511, 8.396,
-27.519, 33.384, 21.839, -2.177, -10.203, -2.967, -23.247, -8.624,
16.054, -35.361, -5.490, 3.066, 2.863, -22.787, -22.852, 22.575,
-23.699, 20.964, -8.856, 22.387, -7.630, -22.538, 17.922, 0.443,
29.763, 18.635, -3.797, -8.202, 1.259, 4.595, -16.844, 17.630,
-7.156, -7.669, -10.022, 5.412, -13.050, 3.491, 56.123, -0.281,
-7.889, -32.563, 1.796, -21.393, -6.720, 3.823, -33.829, 3.941,
6.882, -25.151, -7.055, -35.822, 32.301, 7.403, -2.800, -2.477,
23.420, -1.092, 7.408, 31.164, -6.132, -21.061, -15.699, 29.365,
2.620, -9.255, 20.264, 20.750, -8.722, -18.647, -30.619, -35.086,
-4.508, -17.073, 37.961, 1.962, -38.052, 29.166, 4.025, 14.891,
14.432, 6.722, 11.258, 5.566, -21.336, 8.126, 21.269, -3.410,
11.817, 9.183, 37.104, -4.264, -5.049, -1.547, -1.257, -44.661,
-12.061, 6.789, 0.626, -15.196, -12.504, -6.321, -15.240, -9.470,
-9.997, 18.699, 21.119, 19.463, 9.325, -13.375, 19.988, -5.494,
1.252, 27.556, 2.471, 5.737, -27.464, 10.531, -18.809, 21.030,
-2.901, -43.932, -6.369, -3.769, 10.501, 14.202, -5.764, 21.049,
-62.550, -13.488, -21.456, -24.292, 19.985, 17.375, -14.724,
24.352, 2.821, -7.642, -13.067, -14.774, 10.247, 13.794, 5.561,
-40.213, 6.718, 12.099, -12.593, 1.656, -36.486, -23.808, -5.693,
-5.404, 7.825, -22.947, -6.033, -9.004, 11.351, 29.212, 35.210,
-30.578, -0.169, -21.459, -0.504, 9.250, 2.421, -0.189, 30.452,
15.211, -4.662, 1.276, 18.209, 12.987, -7.710, -34.714, -22.902,
3.711, -34.939, -2.257, -8.280, 20.776, -25.570, -37.844, -7.602,
13.487, 22.190, -17.395, 10.197, -21.437])
# 편차의 합은 항상 0
(data-np.mean(data)).sum()
# 거의 0
-7.815970093361102e-12
x = [1,2,3,4,5]
# 표본 분산(모분산보다 항상 크게나온다.)
np.var(x, ddof =1) # ddof=1 표본분산
pd.Series(x).var(ddof=1)
# 모분산
np.var(x, ddof = 0) # ddof=0 모분산
# 모분산
np.array(x).var()
pd.Series(x).var(ddof =0)
2.5
2.500
2.0
2.0
2.000
x = [1,2,3,4,5]
# 표본 표준편차 (S)
np.std(x, ddof =1) # ddof=1 표본 표준편차
pd.Series(x).std(ddof=1)
# 모표준편차 (sigma)
np.std(x, ddof = 0) # ddof=0 모 표준편차
# 모표준편차
np.array(x).std()
pd.Series(x).std(ddof =0)
1.5811388300841898
1.581
1.4142135623730951
1.4142135623730951
1.414
men = [72,74,77,68,66,75]
women = [45,48,52,53,46,50]
print('평균')
np.mean(men)
np.mean(women)
print('표본 표준편차')
np.std(men, ddof=1)
np.std(women, ddof=1)
평균
72.0
49.0
표본 표준편차
4.242640687119285
3.22490309931942
# np.std(x, axis=axis, ddof=ddof) / np.mean(x)
print('남자 변동계수(CV):',np.std(men, ddof=1)/np.mean(men))
print('여자 변동계수(CV):',np.std(women, ddof=1)/np.mean(women))
남자 변동계수(CV): 0.05892556509887895
여자 변동계수(CV): 0.06581434896570246
# scipy.stats.variation
print('남자 변동계수(CV):',variation(men))
print('남자 변동계수(CV):',variation(women))
남자 변동계수(CV): 0.053791435363991905
남자 변동계수(CV): 0.06008000589338671
: scaling(표준화)
df = pd.read_csv('./data/ch2_scores_em.csv',
index_col = 'student number')
df.head()
| english | mathematics | |
|---|---|---|
| student number | ||
| 1 | 42 | 65 |
| 2 | 69 | 80 |
| 3 | 56 | 63 |
| 4 | 41 | 63 |
| 5 | 57 | 76 |
df['english'].describe() # 데이터 정보 describe()
count 50.00
mean 58.38
std 9.80
min 37.00
25% 54.00
50% 57.50
75% 65.00
max 79.00
Name: english, dtype: float64
df['mathematics'].describe()
count 50.000
mean 78.880
std 8.414
min 57.000
25% 76.000
50% 80.000
75% 84.000
max 94.000
Name: mathematics, dtype: float64
df.describe()
| english | mathematics | |
|---|---|---|
| count | 50.00 | 50.000 |
| mean | 58.38 | 78.880 |
| std | 9.80 | 8.414 |
| min | 37.00 | 57.000 |
| 25% | 54.00 | 76.000 |
| 50% | 57.50 | 80.000 |
| 75% | 65.00 | 84.000 |
| max | 79.00 | 94.000 |
: 평균은 0, 표준편차가 1이 된다.
z1 = (df['english']-df['english'].mean())/df['english'].std()
z2 = (df['mathematics']-df['mathematics'].mean())/df['mathematics'].std()
print(z1.min(), z1.max())
print(z2.min(), z2.max())
# -3 ~ 3 사이의 값으로 분포된다.
-2.1816743772942324 2.104121873704727
-2.600313324789425 1.796925844187209
z1.mean(), z1.std()
(-0.000, 1.000)
s1 = (df['english']-df['english'].min())/(df['english'].max() - df['english'].min())
s2 = (df['mathematics']-df['mathematics'].min())/(df['mathematics'].max() - df['mathematics'].min())
print('eng :', s1.min(), s1.max())
print('math :', s2.min(), s2.max())
eng : 0.0 1.0
math : 0.0 1.0
df.head()
| english | mathematics | |
|---|---|---|
| student number | ||
| 1 | 42 | 65 |
| 2 | 69 | 80 |
| 3 | 56 | 63 |
| 4 | 41 | 63 |
| 5 | 57 | 76 |
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
S = scaler.fit_transform(df)
pd.DataFrame(S, columns=df.columns, index=df.index).head()
| english | mathematics | |
|---|---|---|
| student number | ||
| 1 | 0.119 | 0.216 |
| 2 | 0.762 | 0.622 |
| 3 | 0.452 | 0.162 |
| 4 | 0.095 | 0.162 |
| 5 | 0.476 | 0.514 |
from matplotlib import pyplot as plt
%matplotlib inline
# 오른쪽으로 꼬리가 긴분포(right skwed, positive)
x1 = [1] * 30 + [2] * 20 + [3] * 20 + [4] * 15 + [5] * 15
# 좌우 대칭 분포
x2 = [1] * 15 + [2] * 20 + [3] * 30 + [4] * 20 + [5] * 15
# 왼쪽으로 꼬리가 긴분포(left skwed, negative)
x3 = [1] * 15 + [2] * 15 + [3] * 20 + [4] * 20 + [5] * 30
x1[:10]
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
pd.Series(x1).value_counts(sort=False)
1 30
2 20
3 20
4 15
5 15
dtype: int64
plt.subplot(221)
pd.Series(x1).value_counts(sort=False).plot(kind='bar')
plt.subplot(222)
pd.Series(x2).value_counts(sort=False).plot(kind='bar')
plt.subplot(223)
pd.Series(x3).value_counts(sort=False).plot(kind='bar')
plt.show()
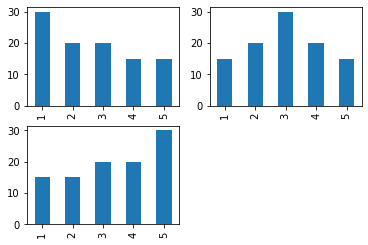
print('오른쪽으로 꼬리가 긴 분포의 왜도:',skew(x1))
print('좌우 대칭 분포 왜도:',skew(x2))
print('온쪽으로 꼬리가 긴 분포의 왜도:',skew(x3))
오른쪽으로 꼬리가 긴 분포의 왜도: 0.3192801008486361
좌우 대칭 분포 왜도: 0.0
온쪽으로 꼬리가 긴 분포의 왜도: -0.31928010084863606
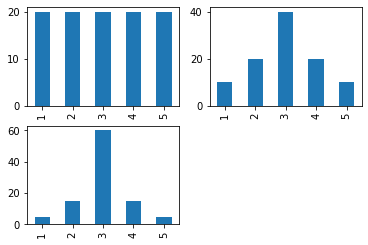
# 균일분포(unifrom dist.)
x1 = [1] * 20 + [2] * 20 + [3] * 20 + [4] * 20 + [5] * 20
# 좌우 대칭 분포(정규분포에 가까움: 뭉툭함)
x2 = [1] * 10 + [2] * 20 + [3] * 40 + [4] * 20 + [5] * 10
# 뾰족한 분포
x3 = [1] * 5 + [2] * 15 + [3] * 60 + [4] * 15 + [5] * 5
plt.subplot(221)
pd.Series(x1).value_counts(sort=False).plot(kind='bar')
plt.subplot(222)
pd.Series(x2).value_counts(sort=False).plot(kind='bar')
plt.subplot(223)
pd.Series(x3).value_counts(sort=False).plot(kind='bar')
print('전혀 뾰족 X (평평) 첨도:',kurtosis(x1))
print('조금 뾰족할 때 첨도:',kurtosis(x2))
print('매우 뾰족할 때 첨도:',kurtosis(x3)) # 뾰족하면 첨도가 높아짐
전혀 뾰족 X (평평) 첨도: -1.3
조금 뾰족할 때 첨도: -0.5
매우 뾰족할 때 첨도: 0.8775510204081636
참고 : https://blog.qlik.com/third-pillar-of-mapping-data-to-visualizations-usage
import numpy as np
import pandas as pd
from scipy.stats import *
df = pd.read_csv('./data/ch2_scores_em.csv',
index_col = 'student number')
df.head()
| english | mathematics | |
|---|---|---|
| student number | ||
| 1 | 42 | 65 |
| 2 | 69 | 80 |
| 3 | 56 | 63 |
| 4 | 41 | 63 |
| 5 | 57 | 76 |
# 50명의 영어 점수 array
eng = df['english']
# Series로 변환하여 describe 표시
eng.describe()
count 50.00
mean 58.38
std 9.80
min 37.00
25% 54.00
50% 57.50
75% 65.00
max 79.00
Name: english, dtype: float64
freq, _ = np.histogram(eng, bins=10, range = (0,100))
freq
array([ 0, 0, 0, 2, 8, 16, 18, 6, 0, 0], dtype=int64)
# 0~10, 10~20, ...
freq_class = list(f'{i} ~ {i+10}' for i in range(0,100,10))
# freq_class를 인덱스로 dataframe을 작성
freq_dist_df = pd.DataFrame({'frequency':freq},
index = pd.Index(freq_class, name='class'))
freq_dist_df
| frequency | |
|---|---|
| class | |
| 0 ~ 10 | 0 |
| 10 ~ 20 | 0 |
| 20 ~ 30 | 0 |
| 30 ~ 40 | 2 |
| 40 ~ 50 | 8 |
| 50 ~ 60 | 16 |
| 60 ~ 70 | 18 |
| 70 ~ 80 | 6 |
| 80 ~ 90 | 0 |
| 90 ~ 100 | 0 |
class_value = [(i+(i+10))//2 for i in range(0,100,10)]
class_value
[5, 15, 25, 35, 45, 55, 65, 75, 85, 95]
rel_freq = freq/freq.sum()
rel_freq
array([0.000, 0.000, 0.000, 0.040, 0.160, 0.320, 0.360, 0.120, 0.000,
0.000])
cum_rel_freq = np.cumsum(rel_freq)
cum_rel_freq
array([0.000, 0.000, 0.000, 0.040, 0.200, 0.520, 0.880, 1.000, 1.000,
1.000])
# 도수 분포표 확장
freq_dist_df['class value'] = class_value
freq_dist_df['relative frequency'] = rel_freq
freq_dist_df['cum. relative freq.'] = cum_rel_freq
freq_dist_df
| frequency | class value | relative frequency | cum. relative freq. | |
|---|---|---|---|---|
| class | ||||
| 0 ~ 10 | 0 | 5 | 0.00 | 0.00 |
| 10 ~ 20 | 0 | 15 | 0.00 | 0.00 |
| 20 ~ 30 | 0 | 25 | 0.00 | 0.00 |
| 30 ~ 40 | 2 | 35 | 0.04 | 0.04 |
| 40 ~ 50 | 8 | 45 | 0.16 | 0.20 |
| 50 ~ 60 | 16 | 55 | 0.32 | 0.52 |
| 60 ~ 70 | 18 | 65 | 0.36 | 0.88 |
| 70 ~ 80 | 6 | 75 | 0.12 | 1.00 |
| 80 ~ 90 | 0 | 85 | 0.00 | 1.00 |
| 90 ~ 100 | 0 | 95 | 0.00 | 1.00 |
import pandas as pd
dataframe=pd.DataFrame({'Attendance': {0: 60, 1: 100, 2: 80,3: 78,4: 95},
'Obtained Marks': {0: 90, 1: 75, 2: 82, 3: 64, 4: 45}})
dataframe
| Attendance | Obtained Marks | |
|---|---|---|
| 0 | 60 | 90 |
| 1 | 100 | 75 |
| 2 | 80 | 82 |
| 3 | 78 | 64 |
| 4 | 95 | 45 |
series = dataframe.idxmax()
series
Attendance 1
Obtained Marks 0
dtype: int64
series = dataframe.idxmin()
series
Attendance 0
Obtained Marks 4
dtype: int64
freq_dist_df.loc[freq_dist_df['frequency'].idxmax(), 'class value']
65
x = np.arange(1,12,1)
x
array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
print(np.percentile(x, 10)) # 백분위수
print(np.quantile(x, 0.1)) # 0 ~ 1 사이의 값으로 입력
2.0
2.0
print(np.percentile(x, 25)) # 25%
print(np.quantile(x, 0.25)) # 하사분위수
3.5
3.5
import matplotlib.pyplot as plt
plt.subplot(221)
plt.hist(eng, bins=25, range=(0,100))
plt.subplot(222)
plt.hist(eng, bins=15, range=(0,100))
plt.subplot(223)
plt.hist(eng, bins=10, range=(0,100))
plt.show()
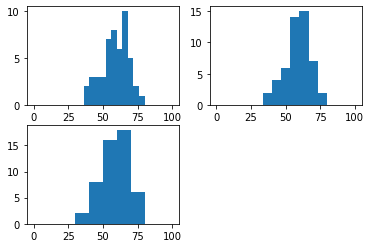
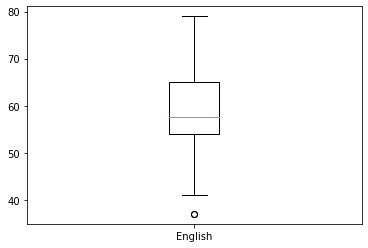
plt.boxplot(eng, labels=['English'])
plt.show()
import numpy as np
import pandas as pd
%precision 3
pd.set_option('precision', 3)
'%.3f'
df = pd.read_csv('./data/ch2_scores_em.csv',
index_col='student number')
df.head()
| english | mathematics | |
|---|---|---|
| student number | ||
| 1 | 42 | 65 |
| 2 | 69 | 80 |
| 3 | 56 | 63 |
| 4 | 41 | 63 |
| 5 | 57 | 76 |
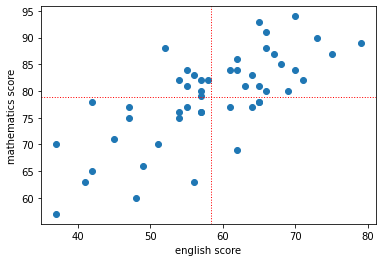
import matplotlib.pyplot as plt
plt.scatter(df['english'], df['mathematics'])
plt.xlabel('english score')
plt.ylabel('mathematics score')
plt.axhline(y=df['mathematics'].mean(), color='r',
linewidth=1,linestyle=':')
plt.axvline(x=df['english'].mean(), color='r',
linewidth=1,linestyle=':')
plt.show()
# 각 과목의 편차 및 과목간 공분산
summary_df = df.copy()
summary_df['eng_dev.'] =\
summary_df['english'] - summary_df['english'].mean()
summary_df['math_dev.'] =\
summary_df['mathematics'] - summary_df['mathematics'].mean()
summary_df['productOfDev.'] =\
summary_df['eng_dev.'] * summary_df['math_dev.']
summary_df.head()
| english | mathematics | eng_dev. | math_dev. | productOfDev. | |
|---|---|---|---|---|---|
| student number | |||||
| 1 | 42 | 65 | -16.38 | -13.88 | 227.354 |
| 2 | 69 | 80 | 10.62 | 1.12 | 11.894 |
| 3 | 56 | 63 | -2.38 | -15.88 | 37.794 |
| 4 | 41 | 63 | -17.38 | -15.88 | 275.994 |
| 5 | 57 | 76 | -1.38 | -2.88 | 3.974 |
summary_df['productOfDev.'].mean()
# 각 학생별 영어와 수학의 공분산 평균이 58.49 이므로 영어와 수학은 양의 상관 관계에 있다.
58.486
cov_mat = np.cov(df['english'],df['mathematics'], ddof=0) # ddof=0 (모집단)
cov_mat
array([[94.116, 58.486],
[58.486, 69.386]])
cov_mat[0,1], cov_mat[1,0]
(58.4856, 58.4856)
cov_mat[0,0] # 영어과목의 분산
94.11560000000001
cov_mat[1,1] # 수학과목의 분산
69.38559999999995
np.var(df['english'], ddof=0), np.var(df['mathematics'], ddof=0)
(94.116, 69.386)
# 수식으로 상관계수 계산
np.cov(df['english'], df['mathematics'], ddof=0)[0, 1] /\
(np.std(df['english']) * np.std(df['mathematics']))
0.7237414863069244
np.corrcoef(df['english'], df['mathematics'])
array([[1.000, 0.724],
[0.724, 1.000]])
df.corr()
| english | mathematics | |
|---|---|---|
| english | 1.000 | 0.724 |
| mathematics | 0.724 | 1.000 |
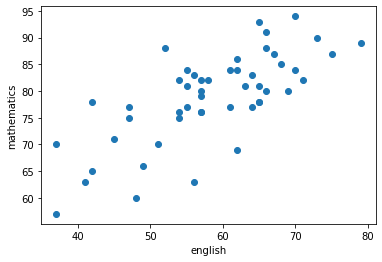
import matplotlib.pyplot as plt
%matplotlib inline
# 산점도
plt.scatter(df['english'],df['mathematics'] )
plt.xlabel('english')
plt.ylabel('mathematics')
plt.show()
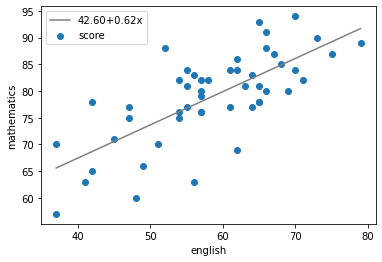
# 계수β_0와β_1를 구한다(기울기와 절편)
poly_fit = np.polyfit(df['english'],df['mathematics'], 1)
# β_0+β_1 x를 반환하는 함수를 작성
poly_1d = np.poly1d(poly_fit)
# 직선을 그리기 위한 x좌표
xs = np.linspace(df['english'].min(), df['english'].max())
# xs에 대응하는 y좌표
ys = poly_1d(xs)
plt.xlabel('english')
plt.ylabel('mathematics')
plt.scatter(df['english'],df['mathematics'], label='score')
plt.plot(xs, ys, color='gray',
label=f'{poly_fit[1]:.2f}+{poly_fit[0]:.2f}x')
# 범례의 표시
plt.legend(loc='upper left')
plt.show()
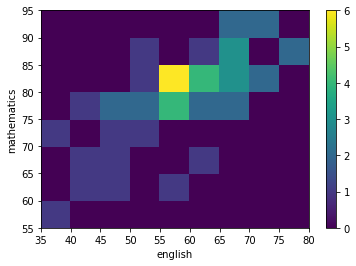
c = plt.hist2d(df['english'], df['mathematics'],
bins=(9, 8), range=[(35,80),(55,95)])
c[3]
plt.xlabel('english')
plt.ylabel('mathematics')
plt.xticks(c[1])
plt.yticks(c[2])
plt.colorbar(c[3])
plt.show()
파일 및 폴더 생성
파일 시스템 탐색
도움말(man -> manual)
명령어 기초
유닉스(Unix)
특정 코드 지연 실행 - DispatchQueue.main.asyncAfter(deadline: )
Naming Conventions
안드로이드 폰과 맥북에어 M1 USB 테더링 성공
Simulator 풀 스크린 사용 방법
10807번 - 개수 세기
프로그래머스 Lv.1 풀이 코드 모음
프로그래머스 Lv.1 풀이 코드 모음
11047번 - 동전 0
11659번 - 구간 합 구하기 4
14888번 - 연산자 끼워넣기
9184번 - 신나는 함수 실행
24416번 - 알고리즘 수업 - 피보나치 수 1
2580번 - 스도쿠
9663번 - N-Queen
15652번 - N과 M (4)
15651번 - N과 M (3)
15650번 - N과 M (2)
25305번 - 커트라인
25304번 - 영수증
3003번 - 킹, 퀸, 룩, 비숍, 나이트, 폰
15649번 - N과 M (1)
2004번 - 조합 0의 개수
1676번 - 팩토리얼 0의 개수
9375번 - 패션왕 신해빈
1010번 - 다리 놓기
11051번 - 이항 계수 2
11050번 - 이항 계수 1
3036번 - 링
2981번 - 검문
1934번 - 최소공배수
2609번 - 최대공약수와 최소공배수
1037번 - 약수
5086번 - 배수와 약수
1358번 - 하키
1004번 - 어린 왕자
1002번 - 터렛
3053번 - 택시 기하학
2477번 - 참외밭
4153번 - 직각삼각형
3009번 - 네 번째 점
1085번 - 직사각형에서 탈출
11478번 - 서로 다른 부분 문자열의 개수
1269번 - 대칭 차집합
1764번 - 듣보잡
10816번 - 숫자 카드 2
1620번 - 나는야 포켓몬 마스터 이다솜
14425번 - 문자열 집합
10815번 - 숫자 카드
18870번 - 좌표 압축
10814번 - 나이순 정렬
1181번 - 단어 정렬
11651번 - 좌표 정렬하기 2
11650번 - 좌표 정렬하기
1427번 - 소트인사이드
2108번 - 통계학
10989번 - 수 정렬하기 3
2751번 - 수 정렬하기 2
2750번 - 수 정렬하기
22.06.25 ~ 27 부산 먹부림 기록
1436번 - 영화감독 숌
1018번 - 체스판 다시 칠하기
7568번 - 덩치
2231번 - 분해합
2798번 - 블랙잭
11729번 - 하노이 탑 이동 순서
2447번 - 별 찍기 - 10
17478번 - 재귀함수가 뭔가요?
10870번 - 피보나치 수 5
10872번 - 팩토리얼
9020번 - 골드바흐의 추측
4948번 - 베르트랑 공준
1929번 - 소수 구하기
11653번 - 소인수분해
2581번 - 소수
1978번 - 소수 찾기
10757번 - 큰 수 A+B
2839번 - 설탕 배달
2775번 - 부녀회장이 될테야
10250번 - ACM 호텔
2869번 - 달팽이는 올라가고 싶다
1193번 - 분수찾기
2292번 - 벌집
1712번 - 손익분기점
1316번 - 그룹 단어 체커
2941번 - 크로아티아 알파벳
5622번 - 다이얼
2908번 - 상수
1152번 - 단어의 개수
1157번 - 단어 공부
2675번 - 문자열 반복
10809번 - 알파벳 찾기
11720번 - 숫자의 합
11654번 - 아스키 코드
1065번 - 한수
4673번 - 셀프 넘버
15596번 - 정수 N개의 합
4344번 - 평균은 넘겠지
8958번 - OX퀴즈
25083번 - 새싹
Spark Bigdata Pipeline
Spark 3일차
Spark 2일차
1546번 - 평균
Spark 1일차
Hadoop🐘
3052번 - 나머지
2577번 - 숫자의 개수
2562번 - 최댓값
10818번 - 최소, 최대
Linux
MongoDB 조회 문제
MongoDB
1110번 - 더하기 사이클
10951번 - A+B - 4
Oracle 3️⃣
ORACLE 연습용 문제 만들기 숙제
10952번 - A+B - 5
Oracle 2️⃣
2480번 - 주사위 세개
Oracle Day1️⃣
Tensorflow
Big Data
2525번 - 오븐 시계
10871번 - X보다 작은 수
2439번 - 별 찍기 - 2
2438번 - 별 찍기 - 1
11022번 - A+B - 8
11021번 - A+B - 7
2742번 - 기찍 N
2741번 - N 찍기
15552번 - 빠른 A+B
8393번 - 합
10950번 - A+B - 3
9️⃣ 2739번 - 구구단
2884번 - 알람 시계
14681번 - 사분면 고르기
⛏크롤링(Crawling)
2753번 - 윤년
Django 복습 4️⃣
Django 복습 3️⃣
💯 9498번 - 시험 성적
1330번 - 두 수 비교하기
✖ 2588번 - 곱셈
➗ 10430번 - 나머지
Django 복습 2️⃣
Django 복습 1
MySQL 복습!
⁉10926번 - ??!
🆎1008번 - A/B
👩🦲 18108번 - 1998년생인 내가 태국에서는 2541년생?!
[Noitce] 고쳐야하거나 틀린 것이 있으면 말씀해주세요!
[Noitce] 고쳐야하거나 틀린 것이 있으면 말씀해주세요!
[Noitce] 고쳐야하거나 틀린 것이 있으면 말씀해주세요!
[Noitce] 고쳐야하거나 틀린 것이 있으면 말씀해주세요!
[Noitce] 고쳐야하거나 틀린 것이 있으면 말씀해주세요!
[Noitce] 고쳐야하거나 틀린 것이 있으면 말씀해주세요!
[Noitce] 고쳐야하거나 틀린 것이 있으면 말씀해주세요!
[Noitce] 고쳐야하거나 틀린 것이 있으면 말씀해주세요!
[Noitce] 고쳐야하거나 틀린 것이 있으면 말씀해주세요!
[Noitce] 고쳐야하거나 틀린 것이 있으면 말씀해주세요!
[Noitce] 고쳐야하거나 틀린 것이 있으면 말씀해주세요!
[Noitce] 고쳐야하거나 틀린 것이 있으면 말씀해주세요!
[Noitce] 고쳐야하거나 틀린 것이 있으면 말씀해주세요!
[Noitce] 고쳐야하거나 틀린 것이 있으면 말씀해주세요!
🎈✨경 축✨🎈
[Noitce] 고쳐야하거나 틀린 것이 있으면 말씀해주세요!
[Noitce] 고쳐야하거나 틀린 것이 있으면 말씀해주세요!
[Noitce] 고쳐야하거나 틀린 것이 있으면 말씀해주세요!
선형 자료구조(1일차에 이어서)
🆎10998번 - A×B
🆎1001번 - A-B
🆎1000번 - A+B
[Noitce] 고쳐야하거나 틀린 것이 있으면 말씀해주세요!
[Noitce] 고쳐야하거나 틀린 것이 있으면 말씀해주세요!
[Noitce] 고쳐야하거나 틀린 것이 있으면 말씀해주세요!
[Noitce] 고쳐야하거나 틀린 것이 있으면 말씀해주세요!
[Noitce] 고쳐야하거나 틀린 것이 있으면 말씀해주세요!
🐶10172번 - 개
[Noitce] 고쳐야하거나 틀린 것이 있으면 말씀해주세요!
[Noitce] 고쳐야하거나 틀린 것이 있으면 말씀해주세요!
[Noitce] 고쳐야하거나 틀린 것이 있으면 말씀해주세요!
🐱10171번 - 고양이
[해당 포스트는 유튜버 나동빈님의 영상을 참고했습니다.]
❤10718번 - We love kriii
🖐2557번 - Hello World
Today I Learned(TIL)📌 (2021.12.31)
Today I Learned(TIL)📌 (2021.12.30)
[Noitce] 고쳐야하거나 틀린 것이 있으면 말씀해주세요!
[Noitce] 고쳐야하거나 틀린 것이 있으면 말씀해주세요!
[Noitce] 고쳐야하거나 틀린 것이 있으면 말씀해주세요!
[Noitce] 고쳐야하거나 틀린 것이 있으면 말씀해주세요!
[Noitce] 고쳐야하거나 틀린 것이 있으면 말씀해주세요!
[Noitce] 고쳐야하거나 틀린 것이 있으면 말씀해주세요!
[Noitce] 고쳐야하거나 틀린 것이 있으면 말씀해주세요!
[Noitce] 고쳐야하거나 틀린 것이 있으면 말씀해주세요!
[Noitce] 고쳐야하거나 틀린 것이 있으면 말씀해주세요!
[Noitce] 고쳐야하거나 틀린 것이 있으면 말씀해주세요!
[Noitce] 고쳐야하거나 틀린 것이 있으면 말씀해주세요!
[Noitce] 고쳐야하거나 틀린 것이 있으면 말씀해주세요!
[Noitce] 고쳐야하거나 틀린 것이 있으면 말씀해주세요!
[Noitce] 고쳐야하거나 틀린 것이 있으면 말씀해주세요!
[Noitce] 고쳐야하거나 틀린 것이 있으면 말씀해주세요!
[Noitce] 고쳐야하거나 틀린 것이 있으면 말씀해주세요!
[Noitce] 고쳐야하거나 틀린 것이 있으면 말씀해주세요!
[Noitce] 고쳐야하거나 틀린 것이 있으면 말씀해주세요!
[Noitce] 고쳐야하거나 틀린 것이 있으면 말씀해주세요!
[noitce!!] 고쳐야하거나 틀린 것이 있으면 말씀해주세요!